全結合層のネットワークや CNN を用いて MNIST 画像認識の実験をした。
実験環境
- tensorflow v2.4.0
- optimizer=‘adam’, loss=‘sparse_categorical_crossentropy’
MNIST のデータの中身
MNIST は 0~9 の手書き文字とそのラベルのデータセットである。 6 万枚の train データと 1 万枚の test データに分かれている。

この記事では、次のように前処理を行った。
import tensorflow as tf
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data()
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
0255 の値を 255 で割ることで 01 の値にすることによって、勾配消失を防ぐことが出来る。
普通に学習
全結合のモデル (その 1)
下記のような全結合が 2 層のモデルを作った。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28,)),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Dense(10, activation='softmax')
])
全パラメータの数は 407,050。
学習条件はこんな感じ
model.fit(X_train, y_train, epochs=50, validation_split=0.1, batch_size=32)
学習履歴と最終的な正解率と損失関数の値は次のようになった。
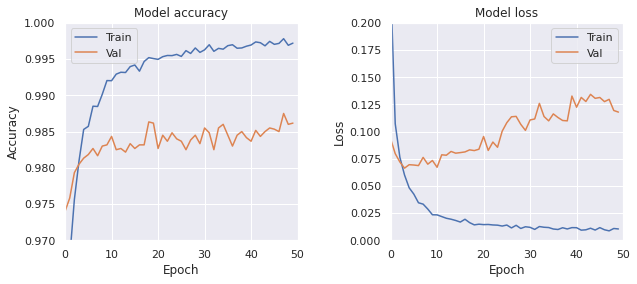
- Train, loss: 0.0102, accuracy: 0.9975
- Test, loss: 0.1410, accuracy: 0.9847
Test データに対する正解率は 98.47%になった。
validation の損失関数がepoch=5で最小になり、epoch=50はその 2 倍ぐらいになっている。
全結合のモデル (その 2)
中間層 512 から 2048 に増やした。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28,)),
tf.keras.layers.Dense(2048, activation='relu'),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Dense(10, activation='softmax')
])
全パラメータの数は 1,628,170。
model.fit(X_train, y_train, epochs=50, validation_split=0.1, batch_size=32 )
学習結果は次のようになった。
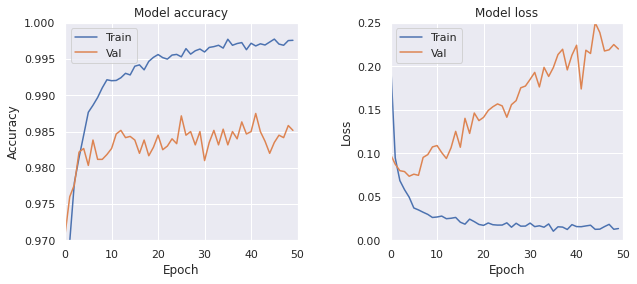
- Train, loss: 0.0144, accuracy: 0.9975
- Test, loss: 0.2275, accuracy: 0.9833
パラメータ数を増やしても正解率は上がっておらず、むしろ test データに対する正解率は下がっている。 過剰適合していることが考えられる。
畳み込みのモデル (その 1)
下記のように全結合層の前に Conv と MaxPool 層を入れたモデルを作成した。
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (5, 5), padding='same', input_shape=(28, 28, 1), activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Dense(10, activation='softmax')
])
全パラメータの数は 1,611,690。
model.fit(X_train, y_train, epochs=50, validation_split=0.1, batch_size=32 )
学習結果は次のようになった。
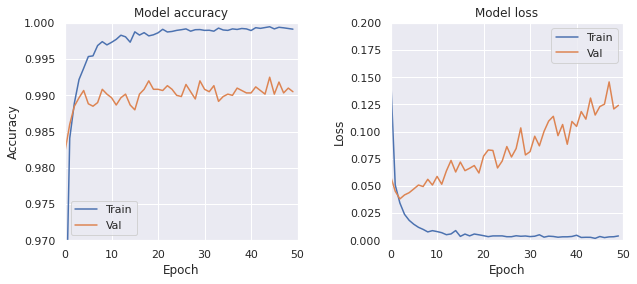
- Train, loss: 0.0027, accuracy: 0.9994
- Test, loss: 0.1221, accuracy: 0.9879
損失関数の収束速度が全結合に比べて速くなった。 また、損失関数が良く小さくなった。
畳み込みのモデル (その 2)
下記のように全結合層の前に Conv と MaxPool 層を複数積み重ねた入れたモデルを作成した。
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), padding='same', input_shape=(28, 28, 1), activation='relu'),
tf.keras.layers.Conv2D(32, (3, 3), padding='same', activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2)),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
tf.keras.layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
tf.keras.layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2)),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Conv2D(128, (3, 3), padding='same', activation='relu'),
tf.keras.layers.Conv2D(128, (3, 3), padding='same', activation='relu'),
tf.keras.layers.Conv2D(128, (3, 3), padding='same', activation='relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2)),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Dense(10, activation='softmax')
])
全パラメータの数は 1,066,410。
model.fit(X_train, y_train, epochs=50, validation_split=0.1, batch_size=32 )
学習結果は次のようになった。
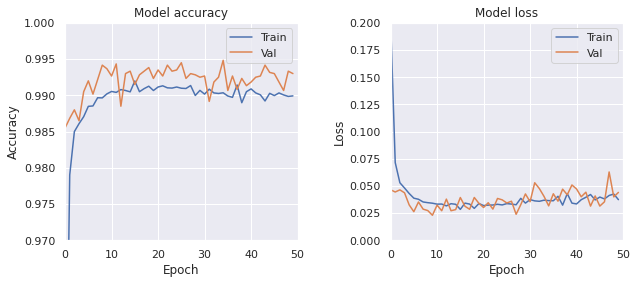
- Train, loss: 0.0374, accuracy: 0.9899
- Test, loss: 0.0138, accuracy: 0.9934
Dropout 層が多いからなのか Train の acc が Val の acc より低くなっている。 またなぜか、学習を進めると微妙に train データの損失関数の値が上昇してる気がする。
結果まとめ
| モデル | パラメータ数 | train loss | train acc | test loss | test acc |
|---|---|---|---|---|---|
| 全結合 1 | 407,050 | 0.0102 | 0.9975 | 0.1410 | 0.9847 |
| 全結合 2 | 1,628,170 | 0.0144 | 0.9975 | 0.2275 | 0.9833 |
| 畳み込み 1 | 1,611,690 | 0.0027 | 0.9994 | 0.1221 | 0.9879 |
| 畳み込み 2 | 1,066,410 | 0.0374 | 0.9899 | 0.0138 | 0.9934 |
ラベルをシャッフル
さて、ラベルをシャッフルして学習してみる。 Tensorflow では次のようにすることでモデルをシャッフル出来る。
y_train_shuffle = tf.random.shuffle(y_train)
こんな感じでシャッフル出来た。

全結合のモデル (その 1)
今回は学習に時間がかかるので epoch 数を増やした。
model.fit(X_train, y_train_shuffle, epochs=500, validation_split=0.1, batch_size=32)
学習履歴と最終的な正解率と損失関数の値は次のようになりました。
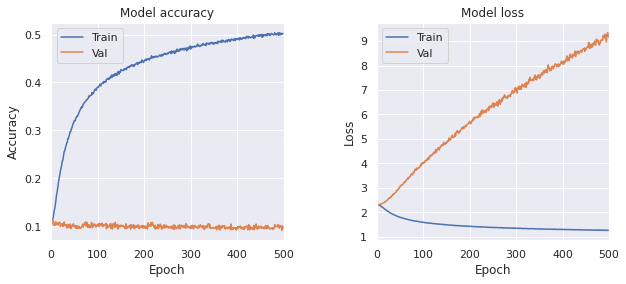
- Train, loss: 1.2545, accuracy: 0.5025
- Test, loss: 8.9777, accuracy: 0.1138
結果として train データに関しては 50%で当てられるぐらいまで学習出来ました。 これは、すべての train データ(5.4 万)の画像とラベルの対応をすべて覚えるという作業を 50%ぐらいこなせるぐらい自由度の高いモデルであるということを意味しています。 また、画像とラベルに関係はないので、validation データに関する正解率が 10%になっています。 さらに、validation データの損失関数が epoch に伴って大きくなっています。
全結合のモデル (その 2)
model.fit(X_train, y_train_shuffle, epochs=500, validation_split=0.1, batch_size=32)
学習結果は次のようになった。
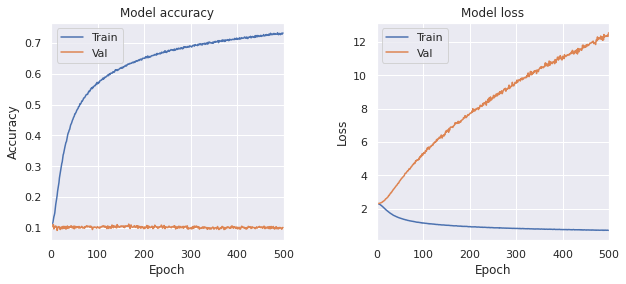
- Train, loss: 0.7056, accuracy: 0.7322
- Test, loss: 8.0285, accuracy: 0.1152
畳み込みのモデル (その 1)
model.fit(X_train, y_train_shuffle, epochs=500, validation_split=0.1, batch_size=32)
学習結果は次のようになった。
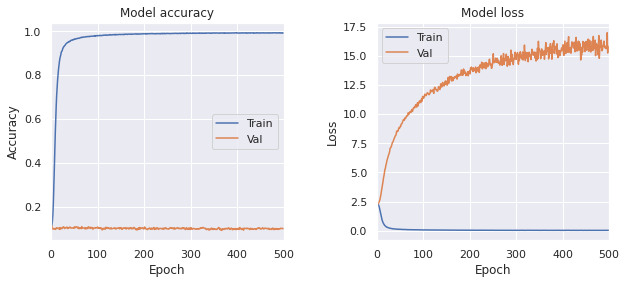
- Train, loss: 0.0328, accuracy: 0.9918
- Test, loss: 13.3561, accuracy: 0.1016
全結合のモデルに比べて学習が速い。 さらに全部の画像を暗記するという問題に関しても 99.18%で成功している。
畳み込みのモデル (その 2)
model.fit(X_train, y_train_shuffle, epochs=500, validation_split=0.1, batch_size=32)
学習結果は次のようになった。
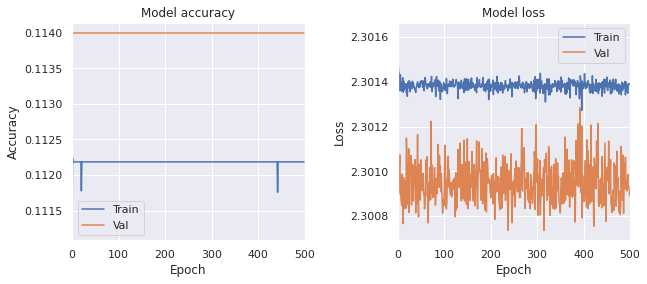
- Train, loss: 2.3015, accuracy: 0.1102
- Test, loss: 2.3010, accuracy: 0.1135
ほぼ学習が進んでない。 Dropout 層を消しても学習は進まなかった。
結果まとめ
| モデル | パラメータ数 | train loss | train acc | test loss | test acc |
|---|---|---|---|---|---|
| 全結合 1 | 407,050 | 1.2545 | 0.5025 | 8.9777 | 0.1138 |
| 全結合 2 | 1,628,170 | 0.7056 | 0.7322 | 8.0285 | 0.1152 |
| 畳み込み 1 | 1,611,690 | 0.0328 | 0.9918 | 13.3561 | 0.1016 |
| 畳み込み 2 | 1,066,410 | 2.3015 | 0.1102 | 2.3010 | 0.1135 |